Flink数据传输状态一致性,Checkpoint的设置,数据容错机制
”Flink 容错机制“ 的搜索结果
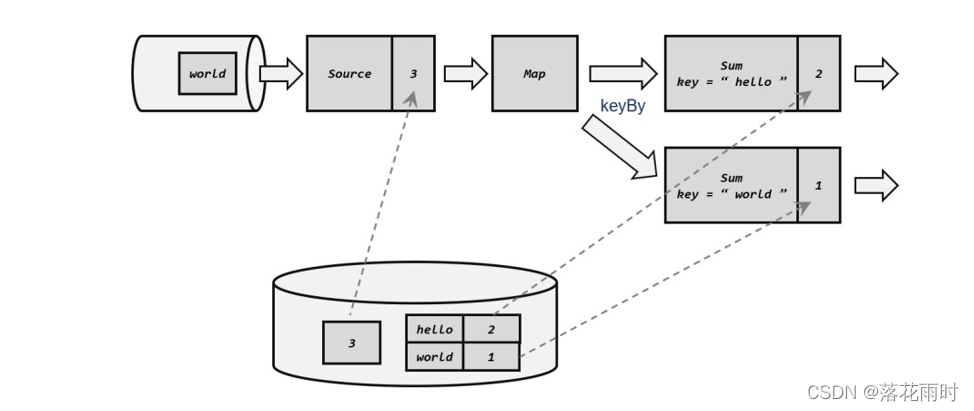
计算任务的结果不仅仅依赖于输入,还依赖于它的当前状态,其实大多数的计算都是有状态的计算。比如wordcount,给一些word,其计算它的count,这是一个很常见的业务场景。count做为输出,在计算的过程中要不断的把输入...
流的barrier是Flink的Checkpoint中的一个核心概念。可以理解成流数据中加入一个个分界线,多个barrier被插入到数据流中,然后作为数据流的一部分随着数据流动( 有点类似于Watermark )。这些barrier不会跨越流中的...
我们只需要让源(source)任务向数据源重新提交偏移量、请求重放数据就可以了(即重新将故障时的数据读入Flink)。当然这需要源任务可以把偏移量作为算子状态保存下来,而且外部数据源能够重置偏移量;
【Flink篇10】Flink之容错机制chekpoint1

flink 容错机制
标签: flink
Apache Flink提供了一种容错机制,可以持续恢复数据流应用程序的状态。该机制确保即使出现故障,程序的状态最终也会反映来自数据流的每条记录(只有一次)。 从容错和消息处理的语义上(at least once, exactly once),...
一、Flink 容错 1.1 State 状态 Flink 实时计算程序为了保证计算过程中,出现异常可以容易,就要将中间的计算结果数据存储起来,如果不保存中间结果那么需要重新计算效率就非常低下,这些中间数据就叫做State。 ...


本文作者:Paul Lin本文链接:2019/07/28/深入理解-Flink-容错机制/版权声明:本博客所有文章除特别声明外,均采用 CC BY-NC-SA 3.0 CN 许可协议。...
Apache Flink 提供了可以恢复数据流应用到一致状态的容错机制。确保在发生故障时,程序的每条记录只会作用于状态一次(exactly-once),当然也可以降级为至少一次(at-least-once)。 容错机制通过持续创建分布式...
IntroduceApache Flink 提供了可以恢复数据流应用到一致状态的容错机制。确保在发生故障时,程序的每条记录只会作用于状态一次(exactly-once),当然也可以降级为至少一次(at-least-once)。容错机制通过持续创建...
Flink 容错机制 保存点和检查点 启用与恢复

推荐文章
- 求助生物源排放模型MEGAN_megan v2.04-程序员宅基地
- java/jsp/ssm网络文学网站【2024年毕设】-程序员宅基地
- 还在用PPT做组织架构图?公司都在用的架构图软件是什么?_书本里印刷的结构图是用什么软件做的-程序员宅基地
- ESP32-C3 BLE5.0 扩展蓝牙名称长度的流程_蓝牙广播名称过长-程序员宅基地
- centos8安装NVIDIA显卡驱动,docker模式运行机器学习_centos8安装显卡驱动-程序员宅基地
- 利用优先级拥抱需求变更_需求优先级反复变化-程序员宅基地
- 素数筛法_筛法求素数-程序员宅基地
- 【深度长文】细思极恐的YouTube可跳过广告-程序员宅基地
- http作业
- KVstore :键值映射存储服务器